IMPLEMENTATION
REFERNCE
[1] Denny Britz. (2015, September 17). Recurrent neural networks tutorial, part1 – introduction to RNNs. [Web log post]. Retrieved from http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
[2] Christopher Olah. (2015, August 27). Understanding LSTM networks. [Web log post]. Retrieved from http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[3] TensorFlow. (n.d.). Retrieved December 11, 2016, from https://www.tensorflow.org/
[4] Bazel. (n.d.). Retrieved December 11, 2016, from https://bazel.build/
[5] Andrej Karpathy. (2015, May 21). The unreasonable effectiveness of recurrent neural netwoks. [Web log post]. Retrieved from http://karpathy.github.io/2015/05/21/rnn-effectiveness/
[6] Kyungyun Cho, Bart van M., Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio. 2014. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation.
[7] Eriko Nurvitadhi, Jaewoong Sim, David Sheffield, Asit Mishra, Srivatsan Krishnan, Debbie Marr. Accelerating Recurrent Neural Networks in Analytics Servers: Comparison of FPGA, CPU, GPU, and ASIC.
Workflow
-
Chose TensorFlow as the framework and learned about its usage.
-
Used TensorFlow to train, valid and test the language model.
-
Modified Java Native Interface to enable inference on Android.
-
Used Google service to do voice recognition.
-
Used Bazel to build the whole project together.
Deep Learning Framework
TensorFlow™ is an open source software library for numerical computation using data flow graphs[3].
It comes with an easy to use Python interface and a no-nonsense C++ interface. So users can easily define new compositions of operations like writing a python function and the low-level data operators are written in C++.
The flexible architecture allows users to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API.
BUILD the model
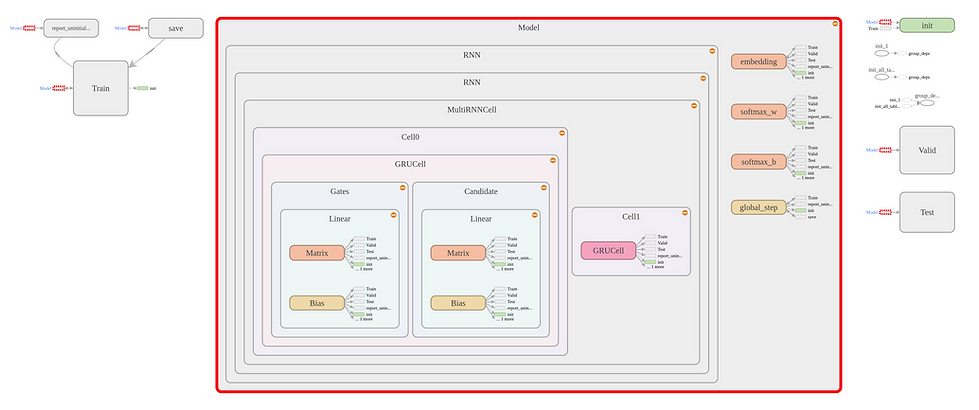
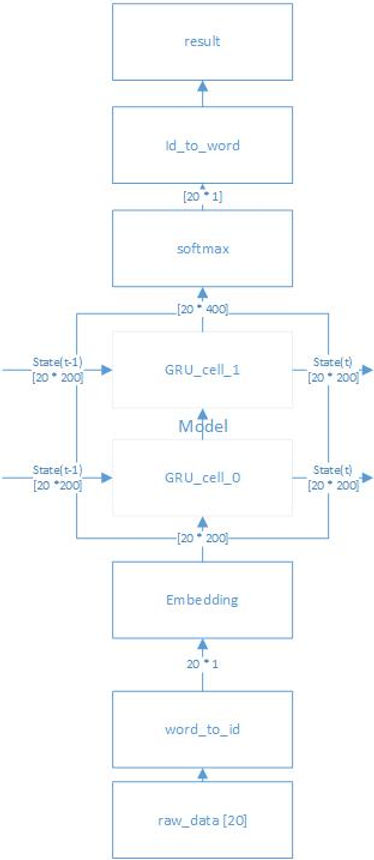
Suppose our input sentence length is always twenty (I will talk about padding later), and the hidden unit size of a single GRU cell is 200. Then the main structure of my model will look like this:
You may be curious about what the embedding node for. This is a common strategy in natural language processing. Because our raw_data, which is the text history, will first be encoded into a unique ID number according to the vocabulary (it is built when you do preprocessing on the data set). However, this kind of encoding normally can't reflect the inner relationship between words. So we need to do word embedding, which is using 200 floating numbers to represent a single word. 200 can be changed and just ensure it is the hidden unit size of your model. It is much like the feature map in CNN theory. And word embedding allows the model to learn the features and relevance of words.
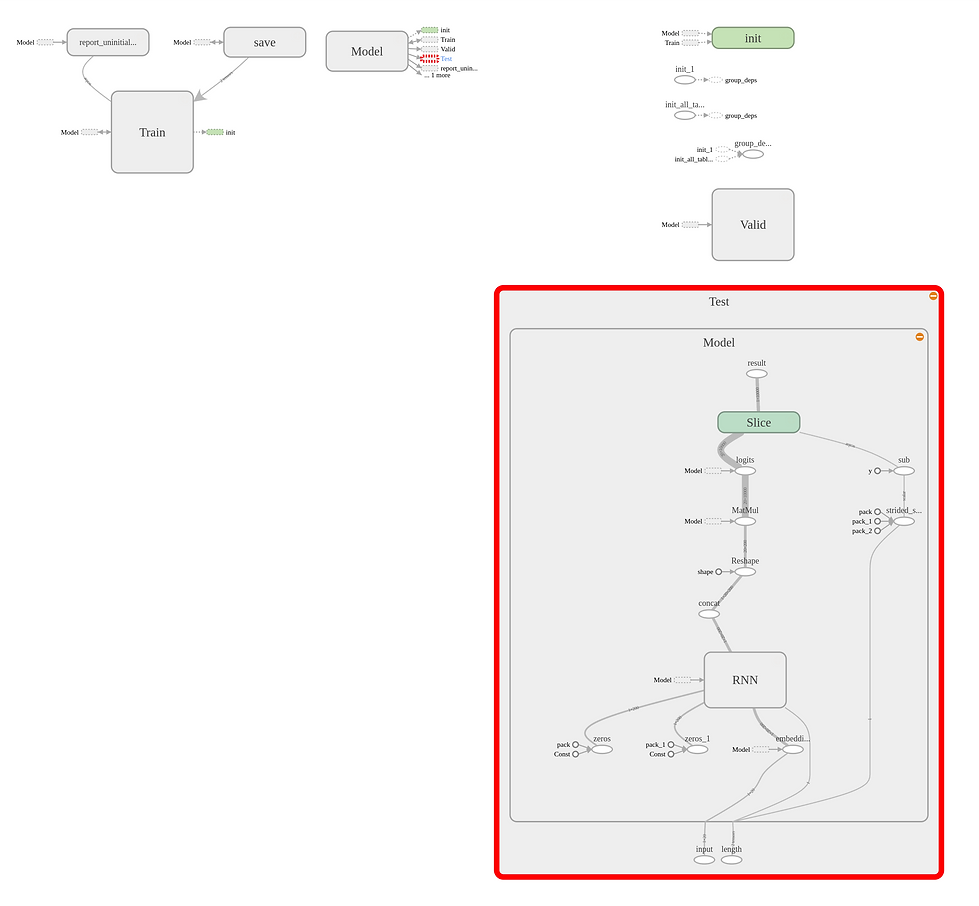
In TensorFlow, a neural network is called a graph. And the multi-dimensional data (tensor) flows though the graph. Defining a graph as above isn't very hard. My graph mainly contains three parts: train, valid and test for different use. But the core composition is the same, which is a two-layer GRU model. In TensorFlow you can define such a model by using API MultiRNNCell to combine two GRU cells together and run tf.nn.dynamic_rnn( ) for inputs with different sequence lengths.
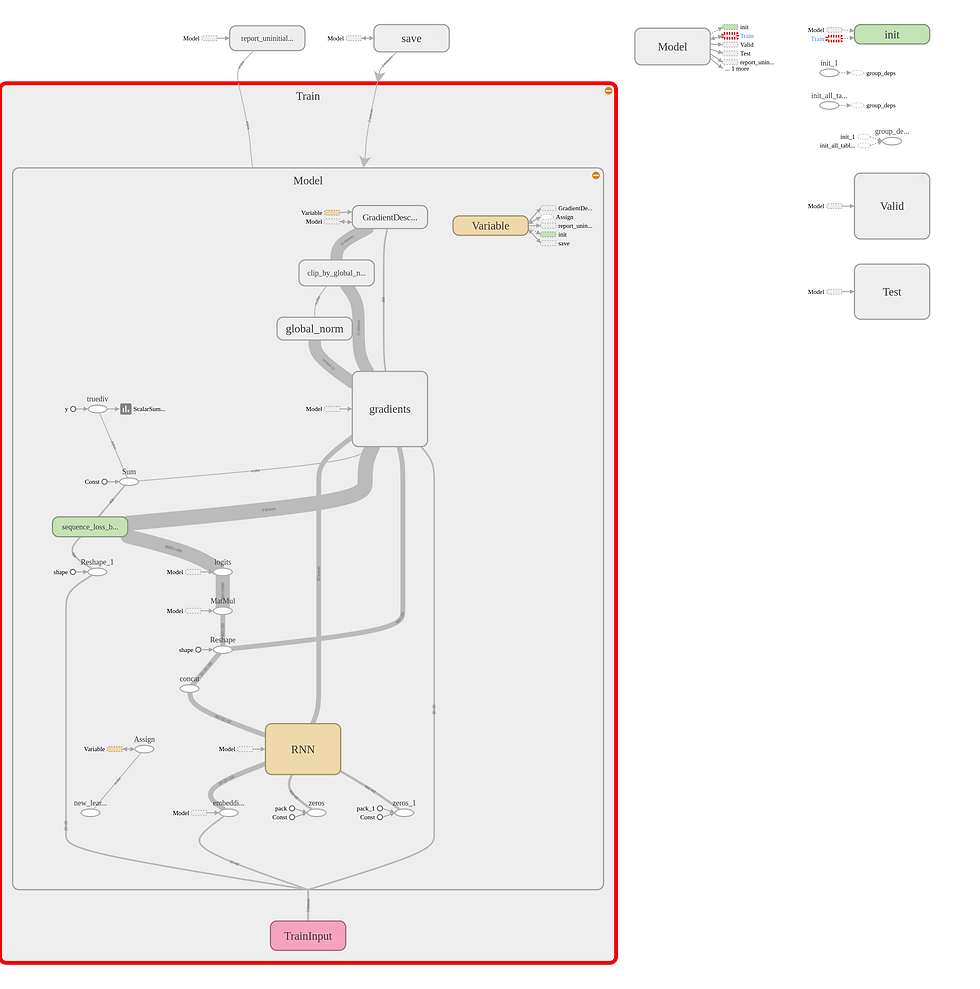
Train & Valid
This is actually the inner content of my train graph. Basically, the train input will go through the embedding node, RNN model and get the predicting result. But different from simple inference, when training, we also need to input the correct answer of each step and calculate the loss along with our results. Then if you are familiar with machine learning, you will know we need to do backward propagation to minimize the loss. But notice that there is gradient vanishing problem in RNNs, so we cannot use TensorFlow optimizer directly. We must manually clip the gradients according to the learning rate we set.
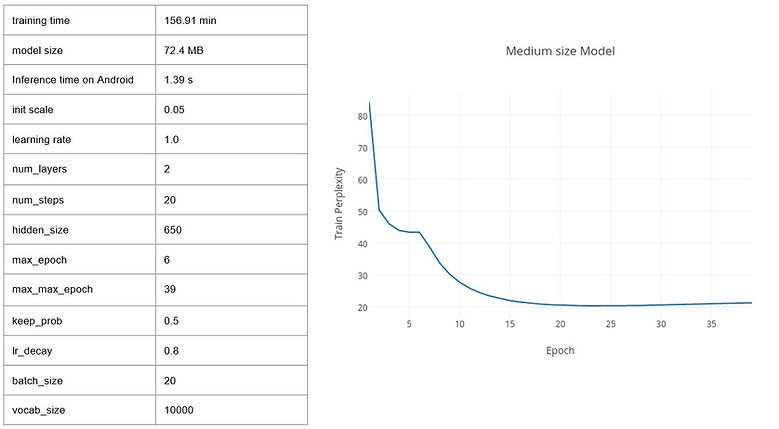
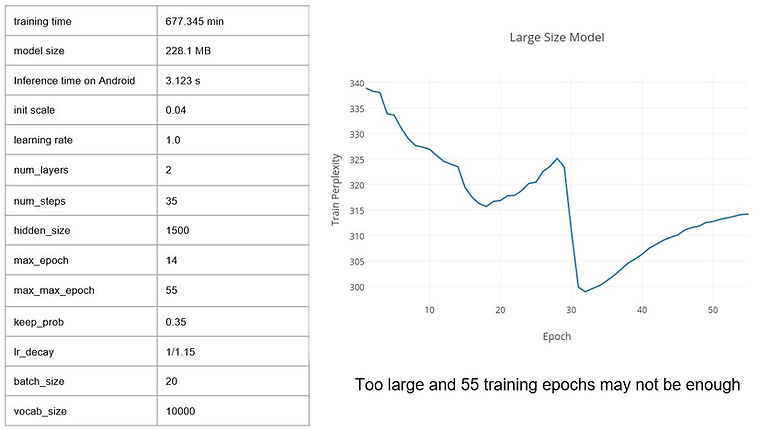
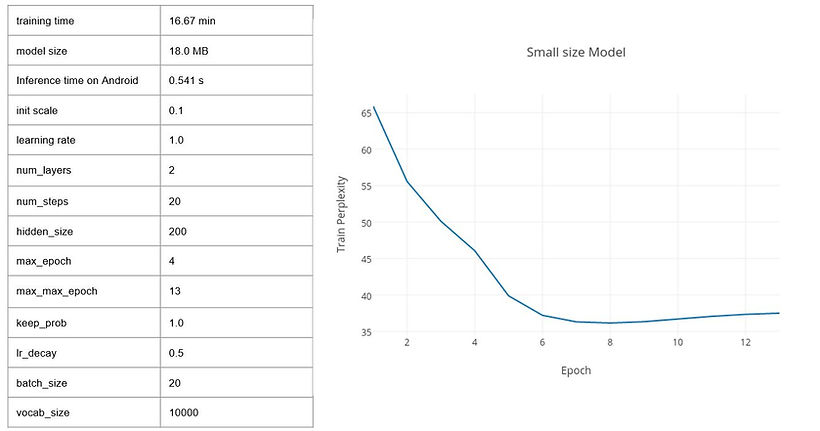
I have tried three data sets to train my language model.
-
Penn Tree Bank: a popular benchmark for measuring quality of language models, whilst being small and relatively fast to train.
-
Reddit Comments: 15,000 longish reddit comments downloaded from a data set available on Google’s BigQuery.
-
Tanaka Corpus: 609724 parallel Japanese-English sentences. I extracted all the English sentences. The sentences are relatively small and simple. As the corpus authors said, it is useful as a source of examples of word usage. I used this in my demo.
Notice that before using the data set, we must do preprocessing including replacing rare words with <unk> and build a vocabulary.
And I trained three different size model, results are shown below.
Test
To test and use the model in practice, there are a few more things to do. Firstly, I define the input sentence and actual sequence length as placeholders and feed them to run instead of reading data from pipeline. Secondly, as I mentioned before, use end of sentence mark <eos> to do padding on the test input sentences to make all of their lengths be twenty. Thirdly, the result tensor during training is actually predicting results of each step. So it's necessary to slice it at index [actual sequence length] as our final predicting result. In the end, we just convert the trained variables to constants and save the graph as TensorFlow protobuf file for Android inference use.
TenSORflow inference interface
TensorFlow has implemented an inference interface for Android. It uses Java Native Interface to allow Android App developers to
-
Initialize the graph
-
Fill nodes in different types
-
Run inference
-
Reads node in different types
Kernel Ops Register
In Android, some of the operators are disabled for computing efficiency. However, we may have these ops or even some new ops in our inference graph. In this case, while loading the graph, Android will complain: No Op Kenel was registered to support Op ‘Some Op’.
So it’s necessary to look up or write the C++ implementation file corresponding to each op and register them in tensorflow/core/kenels/BUILD. Here is a register example:
filegroup(
name = "android_extended_ops_group1",
srcs = [
"Cwise_op_tanh.cc",
"Deep_conv2d.cc",
"Deep_conv2d.h",
"Depthwise_conv_op.cc",
"Dynamic_partition_op.cc",
"Fake_quant_ops.cc",
"Fifo_queue.cc",
"Fifo_queue_op.cc",
"Fused_batch_norm_op.cc",
"Winograd_transform.h",
":android_extended_ops_headers",
],
)
Google voice recognition service
In Android, there is a class named SpeechRecognizer which provides access to the speech recognition service.
-
To use it
Download any Google App with Google voice typing. And then goes to Setting -> Language & keyboards -> Voice input
-> choose Basic Google recognition.
Then in my App, with the permission RECORD_AUDIO, I just need to send an intent to a SpeechRecognizer object to start listening and do inference after getting a result.
-
Problems
This API is not intended to be used for continuous recognition, which would consume a significant amount of battery and bandwidth. I need to keep triggering it to start listening but it’s better to find another service for this App.
Google voice recognition service now supports offline recognition after downloading the specific language package. However, my Android version is too low to support this feature.
Android Studio
Android Studio is the Google official IDE for Android App development. For this project, besides Android SDK, I also need to install Android NDK. It is a toolset that lets you implement parts of your app using native-code languages such as C and C++. So only with Android NDK, I can run TensorFlow Inference Interface.
And my project structure is shown as below.
assets: Contains the model protobuf file and vocabulary file
jni: The TensorFlow inference interface files
model: The TensorFlow model construct files
res: Contains all non-code resources, such as XML layouts, UI strings, and bitmap images.
src/edu/ucla/liangqiu/predictor: Contains the Java source code files.
AndroidManifest.xml: Describes the fundamental characteristics of the app and defines each of its components.
BUILD: Build file for Bazel, which I will introduce in the next section.
Build
Gradle, which is only designed for Android App, can’t build the Android App project along with the graph Protobuf file, inference interface file and all the other source files I need.
Then I found Google build tool Bazel. Google claims it is fast and correct[4].
So all I need to do is to modify the BUILD files under each of my project directories and run ‘Bazel build’ to build the whole project together and download it to my smartphone.Here is a build file example:
android_binary(
name = "word_predictor",
srcs = glob([
"src/**/*.java", -- Android App java source files
]),
assets = glob(["assets/**"]),
assets_dir = "assets", -- Inference graph Protobuf and vocabulary file
custom_package = "edu.ucla.liangqiu.predictor", -- Package name
inline_constants = 1,
manifest = "AndroidManifest.xml", -- Android App Manifest file
resource_files = glob(["res/**"]), -- Android App resource files
tags = [
"Manual",
"Notap",
],
deps = [
":tensorflow_native_libs", -- tensorflow inference interface .so file
"//tensorflow/contrib/android:android_tensorflow_inference_java", -- tensorflow inference interface
],
)